LeetCode 49. Group Anagrams
題目:
根據題目敘述,會給定一個字串陣列 strs,需要把每個字串依據 anagram 做分類放進不同的陣列後回傳。
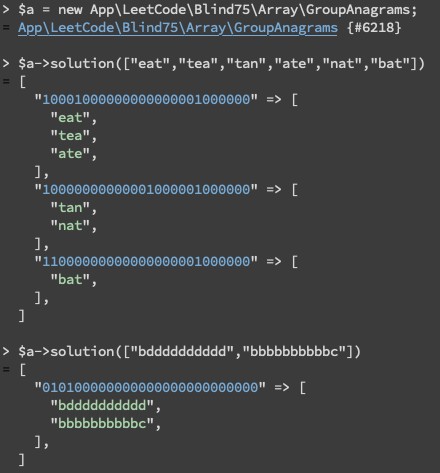
相同 anagram 定義 : 若字串 s 的字元出現頻率與字串 t 相同,則他們為同一個 anagram。例如輸入 strs=[“eat”,“tea”,“tan”,“ate”,“nat”,“bat”],應回傳 [[“bat”],[“nat”,“tan”],[“ate”,“eat”,“tea”]],不看順序。
- 1 <= strs.length <= 10^4
- 0 <= strs[i].length <= 100
- strs 裡的每個字串都只由小寫英文字組成
解法:
原本想到的作法是每個字串做一個字符出現次數表,但這樣的時間複雜度就會變成「字串總數 * (每個字串的最大長度 * 當下有的出現次數表(最大等於字串總數) * 當下有的出現次數表最大長度),光看就不可行。
後來想說既然存出現次數陣列沒比較快,那就改成存排序後的不重複字串,也就是對每個字串做排序後去比較我們存過的不重複字串,時間複雜度會變成「字串總數 * 最大字串排序的時間複雜度」。而因為基本上排序演算法最快也要 O(MlogM),所以當字串總數 N 且最大字串長度 M 時,時間複雜度會是 O(N * MlogM)。
最後是參考別人的答案 : 方法一之所以慢是因為你沒有辦法在 O(K) 的時間複雜度內找到他是否有符合已找過的 K 個 anagram 種類之一,而方法二雖然成功讓其降到 O(K),卻因為需要做排序導致變成 O(MlogM),所以最後這個方法三就是讓你不需排序也能達到 O(K) 甚至更快。
具體來說,我們可以發現題目確保每個字串都是小寫字母,也就是說他們本來就有順序的關係性在,由於 a 的 ASCII 值是 97,而 b 是 98,以此類推到 z,所以可以將每個小寫字母(a~z)減去 a 的值當作索引,剛好就會是索引從 0 開始排到 25 的陣列,你就可以用這個陣列當作有序的字符出現次數表,之後將這個陣列轉成字串當作陣列索引,你就能在 O(1) 的時間複雜度內找到他是否有符合已找過的 anagram 種類之一。
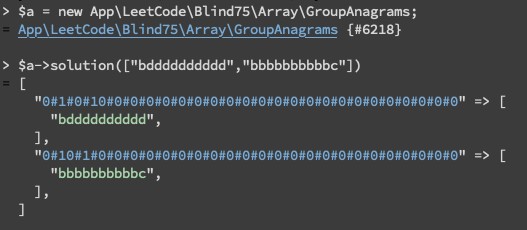
需要注意的陷阱是每個字母出現的次數有可能超過十位數,就代表如果你將陣列轉成字串的作法是直接把次數串在一起就會錯,例如下圖的第二個範例 :
所以說我們在串聯時可以加上特殊標記來區分,例如 :
這樣就不會搞混了。
- 時間複雜度 O(N * M),N 為字串總數,M 為最大字串長度
- 空間複雜度 O(N)
PHP 程式碼:
如果您喜歡我的文章,歡迎幫我在下面按5下讚!感謝您的鼓勵和支持!
 Line
Line buymeacoffee
buymeacoffee





