快取的一致性難題與架構模式 (下)
Meta 是怎麼做的?
- 讀:和 Read aside 一樣。先從 Cache 讀,讀到就回,沒讀到就從 DB 讀然後寫回 Cache。
- 寫:先寫回 DB,接著清掉 Cache
讀寫和 Read aside 一樣,但對 Cache 的操作採用版本控制及 Polaris 系統實作
版本控制 :
所有對 Cache 寫入的請求字段要附加版本資訊
2
3
4
SET x=1 @VERSION=1
SET x=12345 @VERSION=3 (先到,所以先寫入)
SET x=45678 @VERSION=2 (無效,因為剛剛已經先寫版本3了,所以版本2比較低視為無效)缺點:若在 v2 的請求到達之前 v3 的資料就先被清除,v2 就會被成功寫入
Polaris :
是一個基於 Multi-Paxos 演算法實作的系統。
Polaris 是獨立的監控服務。
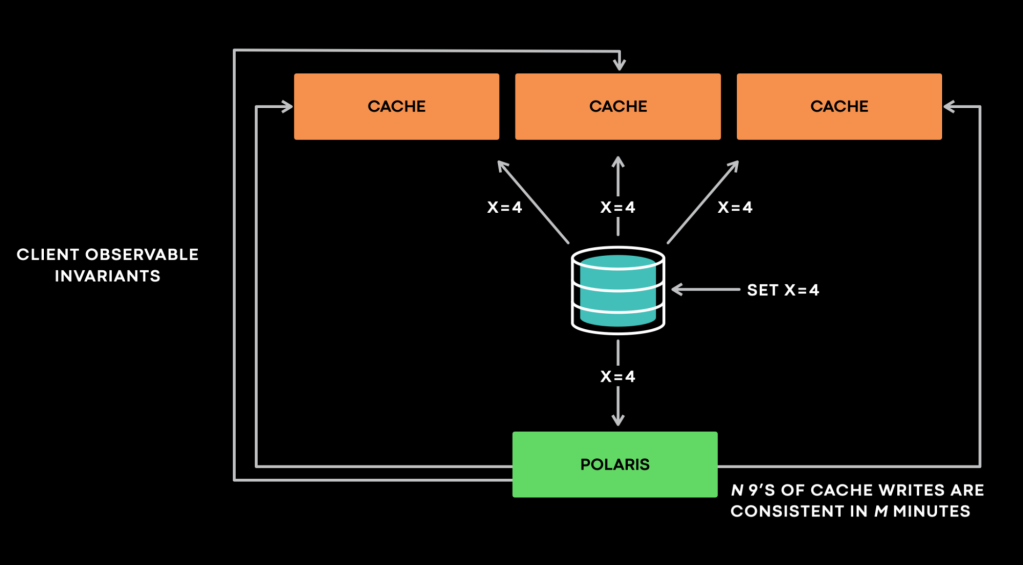
如上圖,當 DB 某資料更新成 x=4 後,會發請求告訴所有 Cache “x=4 @version 4” 的失效事件(invalidation event),表示跟 “x=4 @version 4” 不同的快取已失效,而這時 Polaris 會和其他 Cache 一起收到同樣的請求。接著,Polaris 會去查詢其他 Cache 以便確認他們是否已經更新完成。
假如其中一台 Cache 返回 “x=3 @version 3”, 則 Polaris 會將這台 Cache 標記為不一致,並將這次檢查重新排隊,以便待會再重新檢查一次。
有個特別的地方在於 Polaris 的不一致回報會有 1, 5, 10分鐘內的不同時間尺度,當發現某個 cache 持續 1 分鐘以上不一致後,Polaris 會將此報告歸類為 5 分鐘內的不一致。以 Polaris 的角度來看,當收到不一致的回報時,可能會有不同的情況,例如:
Polaris 收到 “x=4 @version 4” 的失效事件,但是當它查詢 Cache A 時,A 的回覆是 “x” 不存在 。
- 狀況1:x 的 v3 是不可視(invisible),而 v4 是對 x 的最新寫入,所以 Cache A 為不一致。
- 狀況2:x 的 v5 是刪除 x,所以 Polaris 在 v4 還沒檢查完的情況下,Cache A 就已經同步了 v5, 但並不是不一致。
由於兩種狀況互斥,必須查詢 DB 才能區分是狀況1還是狀況2,但是對 DB 的操作成本是非常高的,所以這時候 Polaris 的時間尺度設計就派上用場。
由於真正的緩存不一致和對同一鍵的競速寫操作很少見,對 Cache 重新多做幾次確認就能過濾掉並非真正不一致的情況,而可以彈性設定成例如當 5 分鐘內都還是有不一致的狀況時,才對 DB 做查詢。根據官方使用 Polaris 監測的數據,有 99.99999999% 的緩存寫入在五分鐘內是一致的。而在五分鐘後,100 億次緩存寫入中只有不到 1 次會出現不一致,這個有點饒舌的數據也是因為前面提到的時間尺度設計。
小結 :
Meta 的部落格講了很多架構原理,也因此更能感受到一個高可用性的系統是如何的複雜且高成本,以一般小公司來說可能簡單的 Read Aside 就永遠不會遇到不一致的狀況了,所以終歸是需要依照尖峰的 QPS 和系統能力來判斷是否需要更進一步的拓展,這也是工程師經驗的價值所在。
參考 :
如果您喜歡我的文章,歡迎幫我在下面按5下讚!感謝您的鼓勵和支持!
 Line
Line buymeacoffee
buymeacoffee



