快取的一致性難題與架構模式 (中)
阿里巴巴的開源專案 canal :
- 讀:和 Read Aside 一樣。先從 Cache 讀,讀到就回,沒讀到就從 DB 讀然後寫回 Cache。
- 寫:只寫回 DB,canal 會從 DB 的 binlog 複製到 Cache (canal 扮演 Slave 的角色去監聽 binlog)。
補充 : binlog 是 MySQL 二進位制格式的日誌,只要資料庫有操作,就會寫入 binlog。
MySQL 主從複製 :
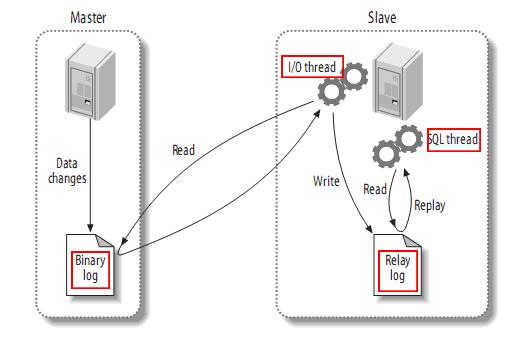
在探討 canal 如何運作之前,我們必須先了解 MySQL 是如何達到主從複製的 :
- Slave 產生 I/O thread 向 Master 請求 binlog。
- Master 會產生一個 log dump thread,負責傳 binlog 給 Slave 的 I/O thread,而在讀取和發送
給 Slave 的過程中會將 binlog 上鎖。- Slave I/O thread 將得到的 binlog 日志寫入 Relay log(中繼日誌) 文件中。
- Slave 產生 SQL thread 讀取 Relay log 文件中的日誌,並解析成具體操作,這樣就能保證主從操作一致,即達成資料一致。
你可能已經發現了他實際上還是會存在不一致的時間,至於具體是多久,可能的影響因素很多,包括網路如何連接、有多少個從機、採用什麼樣的主從架構和同步方式等等…。
大部分人給出的答案都是在同個 lan 下是瞬時的,因為採用獨立的 thread 和 socket 連接,且 binlog 是二進制文件,但是具體的數據官方也沒有提供,可能需要自己測試,可以架好環境後用 SHOW SLAVE STATUS 看 seconds_behind_master 的值。
canal 工作原理 :
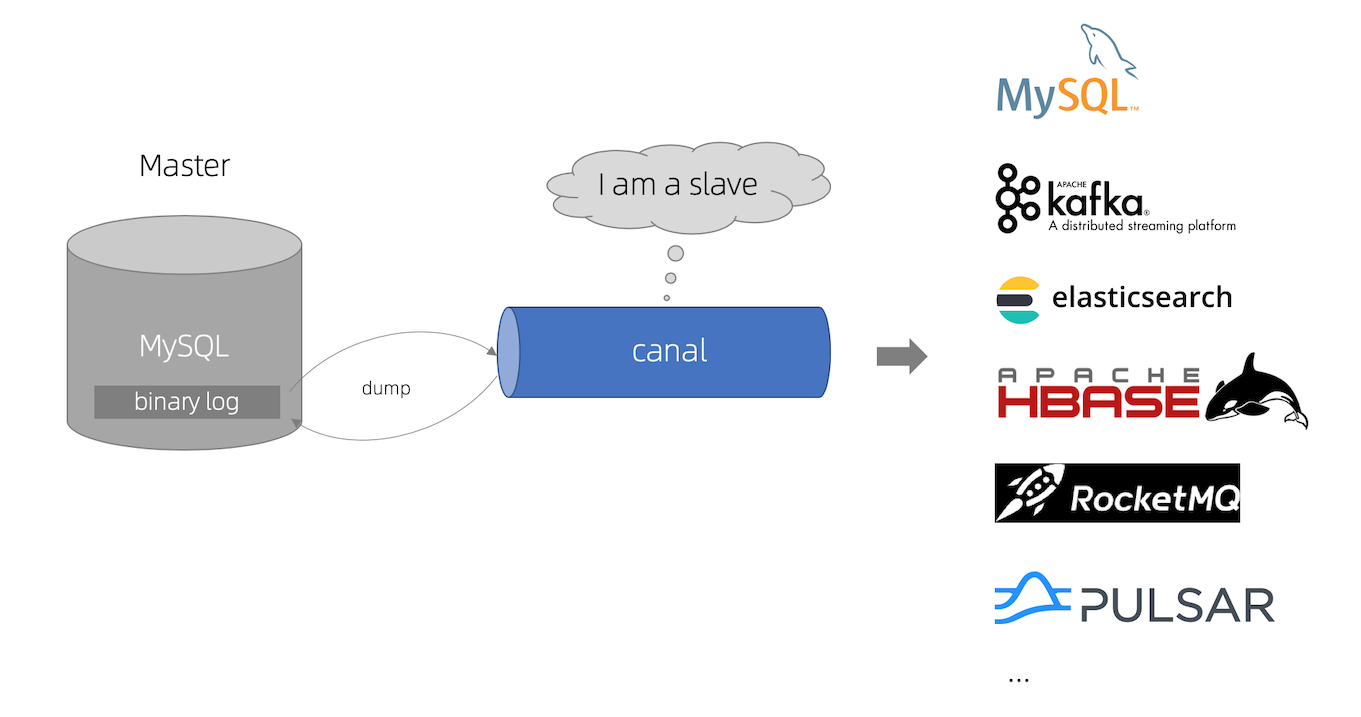
如同上面提到的,MySQL 主從複製是一個成熟且使用者眾多的架構,他的目的也是為了解決分散式架構造成的一致性問題,所以如果我們能讓一個服務偽裝成 Slave 加入這個架構,就能直接沿用這個可靠的架構。
如上圖,canal 模擬 MySQL Slave 的交互協議,讓自己偽裝成 MySQL Slave,並向 MySQL Master 發送 dump 協議,之後 MySQL Master 收到 dump 請求,開始推送 binlog 给 Slave (即 canal),之後 canal 再解析 binlog,就能再去同步到快取或是做其他事情。
小結 :
canal 其實是基於 MySQL 解決一致性的方法作延伸來達成快取架構,但也代表其綁定了 MySQL,如果你是使用其他關聯式資料庫就不適用,可能需要另外找解法。
在之後的文章裡,我們會探討 Meta 是如何設計快取架構的,由於不是基於單一資料庫的延伸,他的架構會更加的複雜,以達到 99.99999999% 的快取寫入一致性。
參考 :
如果您喜歡我的文章,歡迎幫我在下面按5下讚!感謝您的鼓勵和支持!
 Line
Line buymeacoffee
buymeacoffee



