快取的一致性難題與架構模式 (上)
快取是什麼 :
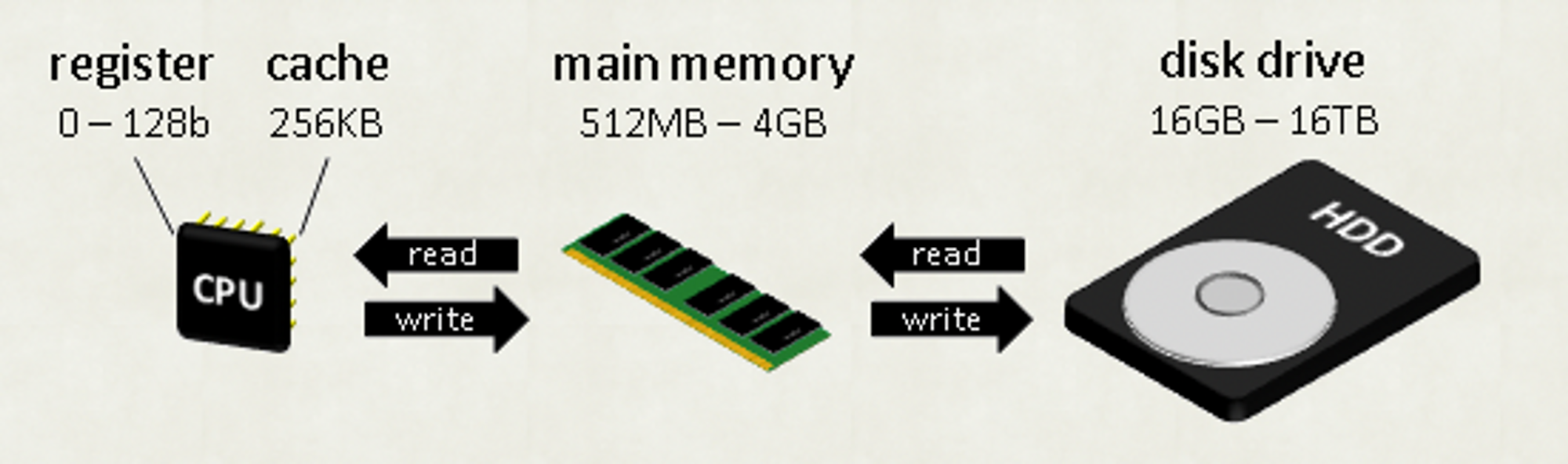
我們都知道電腦的核心運算是由 CPU 負責的,而我們的主要的資料儲存單元是硬碟,由於要在硬碟裡面搜尋資料並帶回來是一件時間成本極高的事,所以就有了將找過的資料暫存起來的概念,如下圖 :
CPU 會先在 CPU Cache 裡尋找資料,當發現沒有之後就會去 main memory(DRAM) 找,再沒有才會去硬碟找。
找到之後就會一路寫回來,這樣你下次要找同樣資料時就不用再跑這麼遠去硬碟找。我們之後會探討的快取就是 main memory(DRAM) 與硬碟的這一塊。
為什麼要使用快取 :
- DB 很慢 : 因為 RDBMS 需要保證 ACID,所以必須等待整個流程跑完。
- DB 很貴 : 由於 RDBMS 的資料儲存在硬碟,會需要更多次 IO,上面已說明過。
- DB 很遠 : 當你的 DB 建在新加坡,對於台灣用戶來說網路距離增加,傳輸速度也慢。
為什麼快取會有一致性難題 :
如果你是分散式系統,那就一定逃不過 CAP 定理,但如果我只在單一台電腦上同時裝 Cache(ex. Redis) 和 DB(ex. MySQL),還會有一致性難題嗎?讓我們接著以實作方式來探討。
快取模式 - Read Aside :
- 讀:先從 Cache 讀,讀到就回,沒讀到就從 DB 讀然後寫回 Cache。
- 寫:先寫回 DB,接著清掉 Cache。
大部分情況都會正常,因為架構很簡單所以是常見的做法。
缺點為極端情況下不符合一致性,因為先對 DB 做事再去同步 Cache,所以同步前的時間差會導致非一致性。
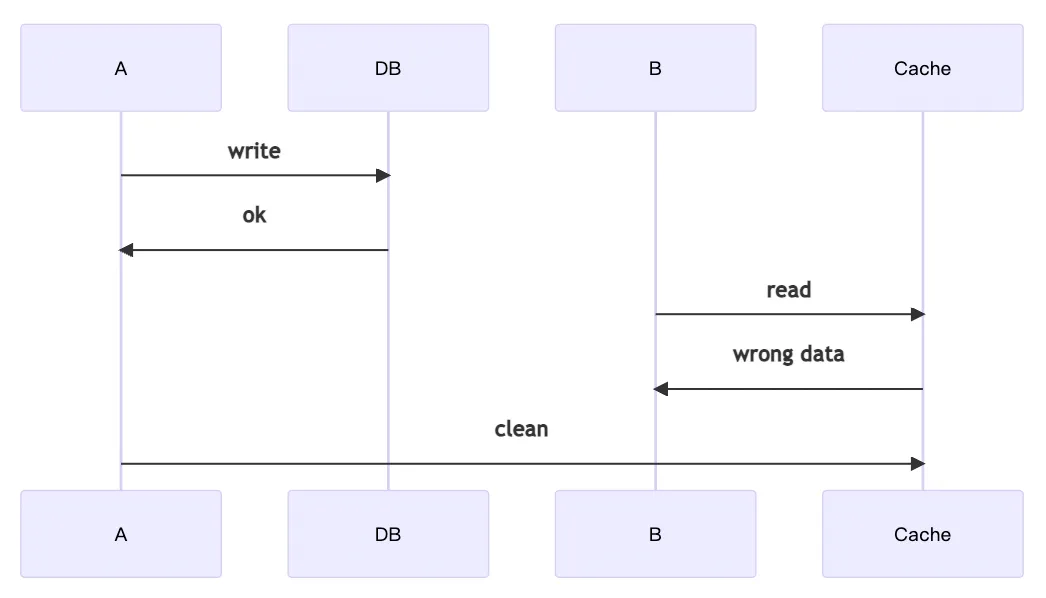
- 問題一 : A 寫了新資料,但還沒同步到 Cache 前 B 就去讀 Cache 的資料,導致不一致。
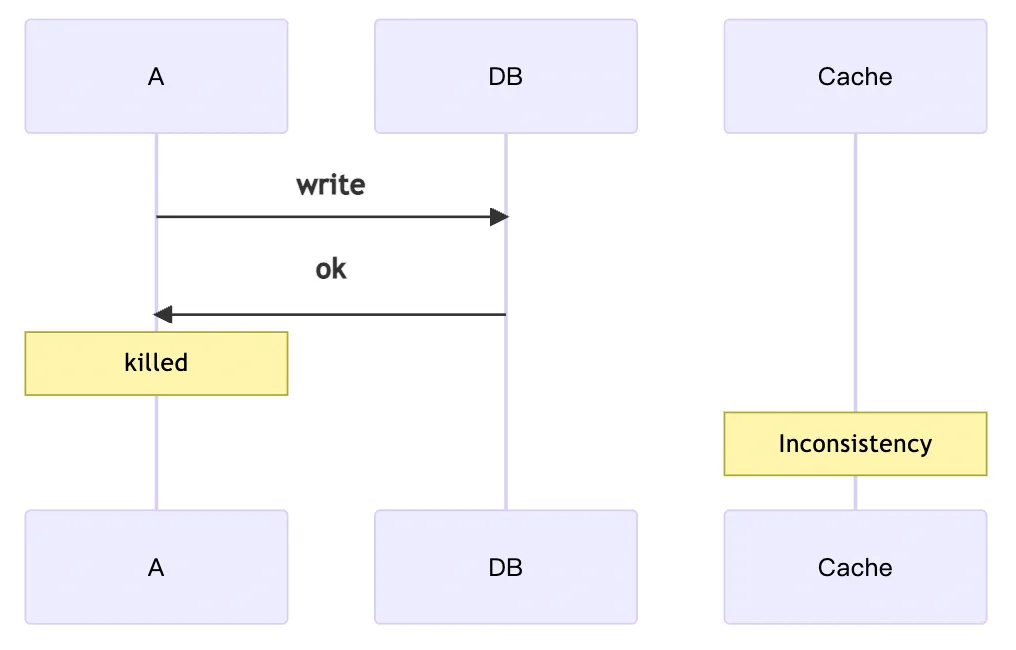
- 問題二 : A 寫了新資料,但要去同步到 Cache 時出了狀況,導致 DB 和 Cache 不一致。
- 問題三 : A 讀資料時發現 Cache 沒資料,所以去 DB 讀,但在寫回 Cache 前 B 就已經更新此資料並清掉Cache 了,這時候 A 才將舊資料寫回 Cache,導致不一致。
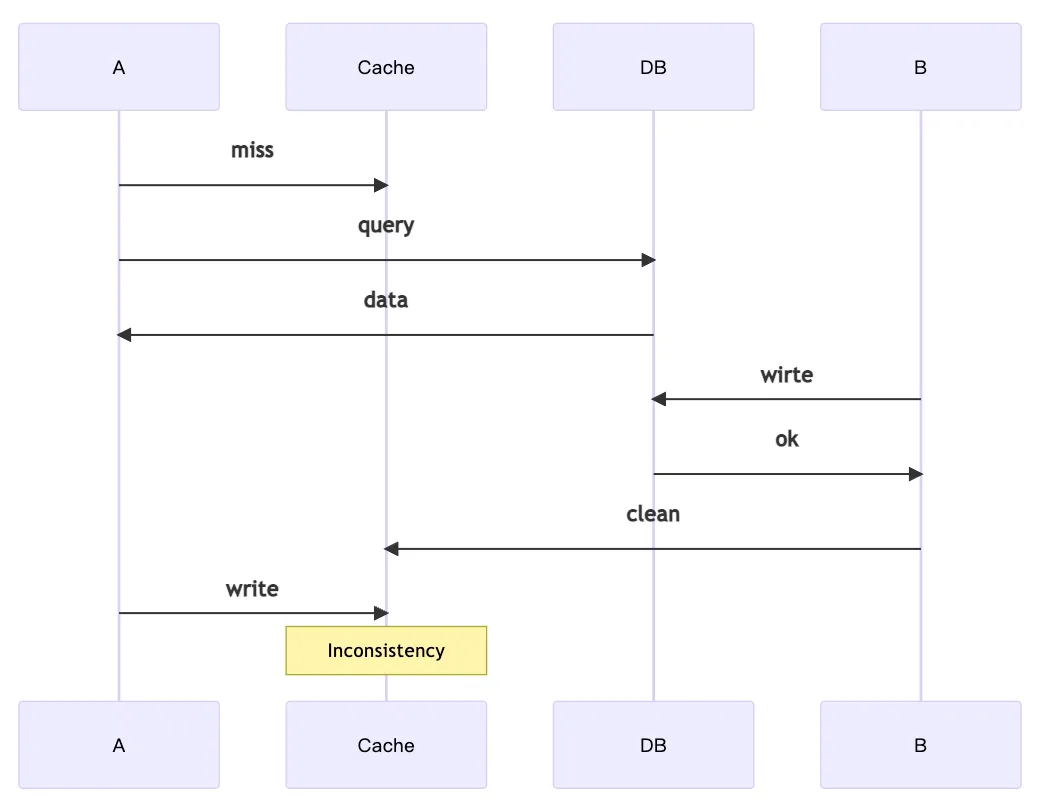
快取模式 - Double Delete :
- 讀:先從 Cache 讀,讀到就回,沒讀到就從 DB 讀然後寫回 Cache。
- 寫:先清掉 Cache 再寫回 DB,接著等一下(依需求調整,例如 0.5s) 再清掉 Cache。
我們可以發現他和 Read Aside 只差在寫的部分,原理是先避免其他人讀到舊資料,之後寫入 DB,先等一下再清掉 Cache 的過程則是為了減少 Read Aside 的問題三發生機率,所以雖然一致的機率提高了,但終究是會在極端情況下不符合一致性。
快取模式 - Read through :
- 讀:先從 Cache 讀,讀到就回,沒讀到就由 Cache 從 DB 讀。
- 寫:無所謂,通常結合 Write Through 或 Write Behind 使用。
注意由 Cache 從 DB 讀的實現 Redis 並不支援,NCache 則是需要收費。
可以自己實作 Data Access Layer(DAL),在 DAL 裡用內部 api 伺服器去決定讀 Cache 還是 DB,而對於應用程式來說並不需要知道到底打了誰或是有沒有緩存,他只要知道可以透過 DAL 快速得到資料就好。
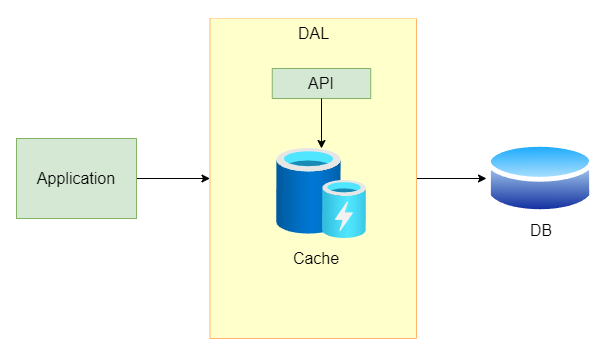
快取模式 - Write through :
- 讀:無所謂,通常結合 Read Through 使用。
- 寫:只更新 Cache,並由 Cache 去更新 DB。
注意跟 Read through 一樣,由 Cache 去更新 DB 的實現 Redis 並不支援,NCache 則是需要收費。
所以一樣可以藉由實作 Data Access Layer(DAL)來實現。也就是說,當你使用 Read through + Write through 來實作快取架構,相當於你都只對 DAL 操作,這樣的優點是可以解決 Read Aside 的問題,但也引發了新的問題 :
- 速度慢,因為你同時要寫完 Cache 和 DB 才算完成。
- 如果你不是用 DAL 而是原生支援 DB 連線的 Cache 的話,如果在 Cache 未寫入 DB 前就斷電重啟的話,那筆尚未更新到 DB 的資料就會永久遺失。
快取模式 - Write Ahead (Behind)(Back) :
- 讀:無所謂,通常結合 Read Through 使用。
- 寫:需實作 DAL,並由 DAL 去更新 Cache 和 DB。
和 Write through 不一樣需實作 DAL,並且會使用 Message Queue 來管理請求,這樣就可以避免 Cache 永久遺失資料的問題,也可以進一步實現對資料庫的批次寫入以減少寫入次數(Write Back),但這樣的架構不好實現,需要處理非常多的細節,除非你真的需要這樣的可靠性,不然直接實作 Read Aside 是最簡單的。
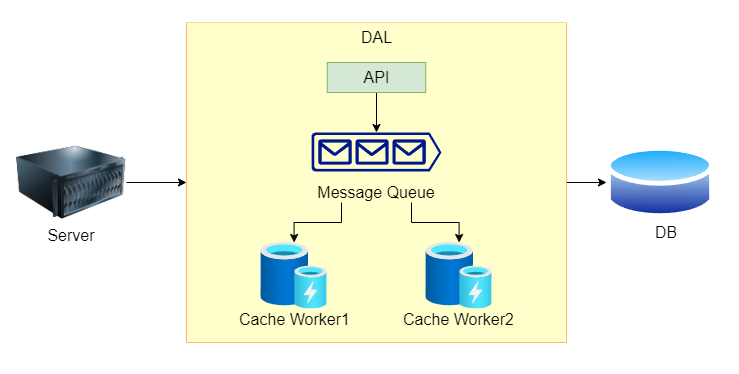
小結 :
介紹了這麼多不同做法,我們應該可以深刻體會一致性的難題有多複雜,以及這些架構背後可能會需要付出的成本,所以在決定你要如何實現快取架構前,你應該先考慮 :
- 你的情境為何?為什麼要使用快取?
- 你的快取機器要求會有多高?會不會需要分散式?
- 比較看重的是一致性還是可用性?
- 哪些動作的延遲是可以接受的?哪些不行?讀跟寫的需求那個比較重?
- 你的快取需要多高的一致性保證?例如 Meta 可以保證 99.99999999% 的快取寫入一致性。
在之後的文章裡,我們會探討阿里巴巴和 Meta 是如何設計快取架構的,雖然絕大多數的公司都不需要實現如此高的一致性,但他們的架構還是值得了解。
參考 :
- I/O-efficient Algorithm
- CPU Cache 原理探討
- 計算機組織與結構
- Consistency between Cache and Database, Part 1
- Consistency between Cache and Database, Part 2
- 資料緩存失效問題
如果您喜歡我的文章,歡迎幫我在下面按5下讚!感謝您的鼓勵和支持!
 Line
Line buymeacoffee
buymeacoffee



